
목록Study (184)
Hayden's Archive
 [Python-matplot] Matplot으로 직선 그리기 / 옵션 / 겹쳐진 그래프 그리기 / 파도 모양 그래프
[Python-matplot] Matplot으로 직선 그리기 / 옵션 / 겹쳐진 그래프 그리기 / 파도 모양 그래프
matplot 시작 Plot 직선 그리기 Plot 그래프에 옵션 추가하기 겹쳐진 그래프 그리기 파도 모양의 그래프 Pandas 데이터를 이용한 Visualization 산점도(Scatter) 그래프 그리기 Subplot 으로 plot(), scatter(), bar() 동시 이용하기 * matplot 시작 matplotlib cmap 검색하고, matplotlib.org/3.1.0/tutorials/colors/colormaps.html 데이터 분석한 다음에 시각화할 때 그래프 적용 tutorial 참고하면 됨. examples에 들어가면 이 안에 거의 모든 그래프가 있음. 문법은 API에 다 있음. 위로↑ * Plot 직선 그리기 위로↑ * Plot 그래프에 옵션 추가하기 위로↑ * 겹쳐진..
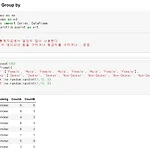 [Python-pandas] 데이터 그룹연산 - groupby() / pivot_table() / 알아두어야 할 함수들
[Python-pandas] 데이터 그룹연산 - groupby() / pivot_table() / 알아두어야 할 함수들
데이터 그룹연산 - groupby() 실전데이터 응용하기 알아두어야 할 함수들 피벗 테이블 pivot_table() 실전데이터 Pivot_Table 응용 문제1 문제2 사용자 함수 정의 * 데이터 그룹연산 - groupby() 위로↑ * 실전데이터 응용하기 위로↑ * 알아두어야 할 함수들 argmin(), argmax() => 굉장히 중요한 함수. 최솟값, 최댓값을 가지고 있는 인덱스를 반환 describe 통계적인 정보를 요약해서 출력해줌 위로↑ * 피벗 테이블 pivot_table() ★중요(엑셀 다룬 사람들은 피벗 테이블 많이 봤을 것) 기존 데이터를 DataFrame으로 받아오면 그걸 변형해서 써야 하는데 그걸 Pivot Table이라고 함 -> 주로 인덱스를 재조정(일종의 그룹핑) ..

 [Python-pandas] DataFrame 누락 데이터 처리
[Python-pandas] DataFrame 누락 데이터 처리
데이터 분석 이전에 데이터 전처리 과정이 중요 -> 누락 데이터를 어떻게 처리할 것인가가 중요. NaN이라고 함. 누락된 데이터 관련 함수 -> isnull / notnull 판다스에서 누락데이터 값은 배제하고 기술 통계 처리. drop은 그냥 없애는 것 dorpna는 누락데이터를 없애는 것 fillna는 누락데이터를 다른 값으로 채우는 것
 [Python-pandas] 데이터프레임(DataFrame) 생성 / 구조 / 컬럼명 변경 및 추가 / 조회(인덱싱, 슬라이싱) / 삭제 / 정렬 / 유용한 함수
[Python-pandas] 데이터프레임(DataFrame) 생성 / 구조 / 컬럼명 변경 및 추가 / 조회(인덱싱, 슬라이싱) / 삭제 / 정렬 / 유용한 함수
DataFrame 생성하기 DataFrame - 구조 확인 DataFrame - 컬럼명 변경 및 추가 DataFrame - 조회하기 (인덱싱, 슬라이싱) drop() - 삭제하기 DataFrame - 정렬하기 실전데이터로 응용하기 알아두면 유용한 함수들 * DataFrame 생성하기 데이터를 로드해올 때 서두르지 말 것. 데이터가 어떻게 생겼는지 먼저 알고 들어가야 함. 그 데이터를 모르면 데이터 분석이 안 됨. 모델을 구축하는 것도 좋지만 어떤 데이터를 input으로 받아들이는지 알고 들어갈 것. 내가 분석하고자 하는, 학습시키고자 하는, 끌어오고자 하는 데이터가 어떤 모양인지 반드시 먼저 확인하고 코드 작성하기! 이 데이터가 어떤 데이터의 성격인지 알려면 이 데이터의 feature(특징=..
 [Python-pandas] 시리즈(Series) 생성, 구조 / 시리즈 값 조회 + 응용 조회 / 시리즈 간의 연산과 누락 데이터 처리 / 시각화
[Python-pandas] 시리즈(Series) 생성, 구조 / 시리즈 값 조회 + 응용 조회 / 시리즈 간의 연산과 누락 데이터 처리 / 시각화
판다스(Pandas) 도입 시리즈(Series) 생성, 구조 확인 시리즈 값 조회하기 응용해서 조회하기 시리즈 간의 연산과 누락 데이터 처리 Series 값을 이용한 시각화 * 판다스(Pandas) 도입 판다스에서 하는 수학적인 계산들을 넘파이꺼 씀. Series(1차원) -> 벡터구조. DataFrame(2차원) -> 행과 열. 행렬(매트릭스)로 자료 보관 Panel(3차원) 데이터 분석에서 인덱스는 행! 판다스의 시리즈(Series)는 일련의 객체를 담을 수 있는 1차원 배열 구조(넘파이 배열과 같음). 값에는 내부적으로 인덱싱이 매겨져있다. 위로↑ * 시리즈(Series) 생성, 구조 확인 위로↑ * 시리즈 값 조회하기 위로↑ * 응용해서 조회하기 위로↑ * 시리즈 간의 연산과 누락 데이터 처리 위..
* 나머지 연산(Modular Arthimetic) - 컴퓨터의 정수는 저장 범위가 한정적 -> 그래서 답을 M으로 나눈 결과를 출력하라는 문제가 종종 나옴 - (A+B)%C 와 (A%C+B%C)%C 는 같고, (A*B)%C 와 (A%C*B %C)%C 는 같다 * 최대공약수(Greatest Common Drivisor = GCD) // 관련 알고리즘 : https://hayden-archive.tistory.com/279 - 서로소(Coprime) : 최대공약수가 1인 두 수 - 최대공약수를 구하는 가장 빠른 방법 -> 유클리드 호제법(Euclidean algorithm) 이용 - 유클리드 호제법 : a를 b로 나눈 나머지를 r이라고 할 때 GCD(a,b) = GCD(b,r) - 이 때 r이 0이면 그 ..
 [Python-matplot] 시각화(Visualization)하기
[Python-matplot] 시각화(Visualization)하기
import matplotlib.pyplot as plt plt.figure(figsize=(10,6)) # 가로사이즈 10, 세로사이즈 6 plt.plot(walk) plt.savefig('walk.png') # 같은 경로에 walk.png 저장됨 plt.show() # 객체 이름이 지저분하게 나와서 이거까지 입력하고 마무리해줌
 [Python-numpy] 인덱싱과 슬라이싱 / Numpy 통계함수
[Python-numpy] 인덱싱과 슬라이싱 / Numpy 통계함수
인덱싱과 슬라이싱 인덱싱만 쓰게 된다면 하나의 데이터(스칼라값)만 추출할 수 있음. - one row, one column을 스칼라값이라고 함. 인덱싱은 스칼라값을 추출하기 위한 방법. 슬라이싱을 쓰려면 반드시 인덱싱이 들어가야 함. 값을 추출하는 일이 비일비재하므로 인덱싱과 슬라이싱 굉장히 중요. 마지막 숫자는 포함되지 않는다. where절 => 3항 연산자와 동일 Numpy 통계함수
 [Python-numpy] Numpy 배열의 생성 / 초기화 / 속성과 기본함수 / 랜덤함수와 Seed값 설정
[Python-numpy] Numpy 배열의 생성 / 초기화 / 속성과 기본함수 / 랜덤함수와 Seed값 설정
벡터와 배열을 위한 넘파이(Numpy) Numpy 배열 생성하기 array() 사용해서 np 배열 생성 랜덤함수 사용해서 np 배열 생성 np 배열과 리스트 비교 배열 초기화 Numpy 배열의 속성과 기본함수(ndim, shape, reshape) 랜덤함수와 seed값 설정하기 * 벡터와 배열을 위한 넘파이(Numpy) 벡터 -> 1차원이다! 데이터 분석에서는 살짝 다루지만(판다스에서 또 나옴) 머신이나 딥에서 넘파이가 많이 나옴. 3차원은 딥에서 다룸. 데이터 분석을 하는데는 2차원을 함. 모든 데이터는 우리가 보기에 난수같은 숫자로 만들어짐. 데이터 -> 보안상 고객 정보를 100만분의 1로 나누고 루트 씌우고 ~~ 형태(0~1 사이의 숫자. 난수처럼 보이는 숫자.)의 줌. -> 그래서 ..