
Hayden's Archive
[Python-numpy] Numpy 배열의 생성 / 초기화 / 속성과 기본함수 / 랜덤함수와 Seed값 설정 본문
< 차례 >
벡터와 배열을 위한 넘파이(Numpy)
Numpy 배열 생성하기
array() 사용해서 np 배열 생성
랜덤함수 사용해서 np 배열 생성
np 배열과 리스트 비교
배열 초기화
Numpy 배열의 속성과 기본함수(ndim, shape, reshape)
랜덤함수와 seed값 설정하기
* 벡터와 배열을 위한 넘파이(Numpy)
벡터 -> 1차원이다!
데이터 분석에서는 살짝 다루지만(판다스에서 또 나옴) 머신이나 딥에서 넘파이가 많이 나옴.
3차원은 딥에서 다룸.
데이터 분석을 하는데는 2차원을 함.
모든 데이터는 우리가 보기에 난수같은 숫자로 만들어짐.
데이터 -> 보안상 고객 정보를 100만분의 1로 나누고 루트 씌우고 ~~ 형태(0~1 사이의 숫자. 난수처럼 보이는 숫자.)의 줌. -> 그래서 원래대로 복구시켜서 진짜 데이터로 봐야 함.
Numpy = Numeric Python
넘파이의 핵심 - 수학적인 연산. 수학적인 값을 1차원적으로 다룬다.
| - numpy : 수학분야 관련 연산 작업시 사용한다. - pandas : 데이터구조 파악, 데이터 정제 및 가공 작업시 사용한다. - scipy : 과학분야에서 사용한다. - matplotlib : 데이터를 다양한 형태로 시각화 할 때 사용한다. (R과 대치됨. 프로그래밍 언어로도 사용이 가능하지만, 파이썬을 쓸 것임. 따라서 matplot은 언어로 안 쓰고 시각화 도구로만 쓰겠음. matplot 쓰다 보면 seaborn까지 쓸 수 있게 되는데 matplot보다 그래프를 더 진하게 그릴 수 있음.) |
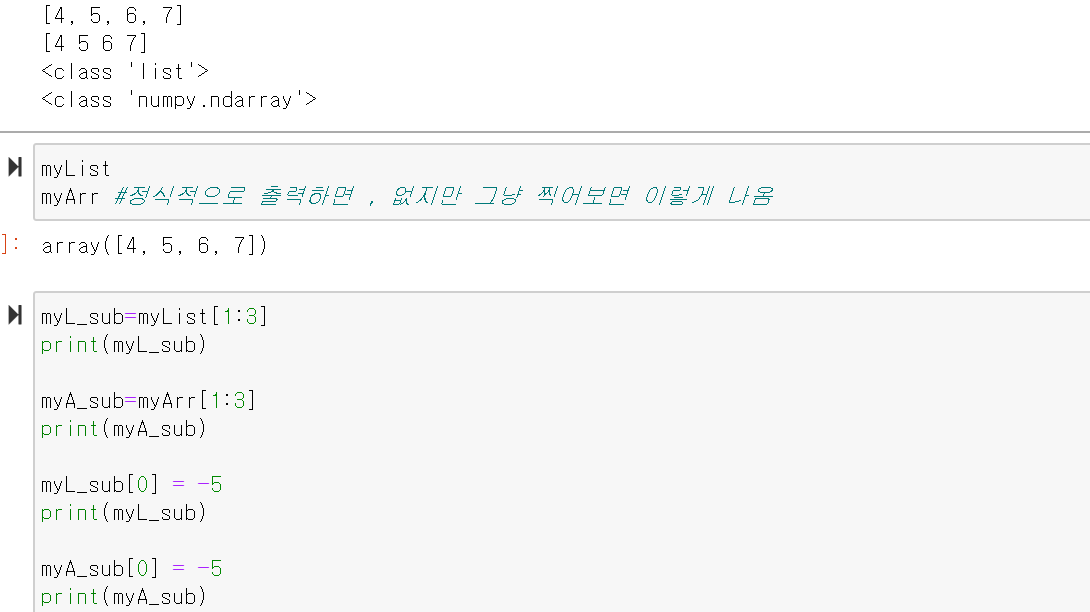
Numpy 배열은 리스트와 똑같음. 리스트에 비해 차이점은 넘파이 배열이 빠르고 메모리 성능이 효율적.
리스트는 원본이 변화가 안 됨. 넘파이는 원본이 변화됨. -> 메모리 효율성이 굉장히 좋다
리스트는 서로 다른 자료형을 가질 수 있지만 넘파이는 동일한 자료형만 가질 수 있음.(굉장히 중요한 특징)
리스트 안 다루고 Numpy 배열을 다루는 이유 : 앞으로 대용량 데이터 다룰 건데 넘파이 배열이 연산 처리와 메모리 관리가 더 뛰어남 (참고 : 빅데이터 처리에서 텐서플로우보다 파이토치를 선호하는 이유? 메모리 효율성이 더 좋음.)
* Numpy 배열 생성하기

넘파이 배열을 만드는 가장 간단한 방법 -> array(), random()
* array() 사용해서 np 배열 생성


* 랜덤함수 사용해서 np 배열 생성
랜덤함수가 왜 많이 다뤄지는가?->개인정보보호를 위해 알아볼 수 없는, 얼핏 보기에 난수와 비슷한 형태로 데이터가 제공될 때가 많으므로(ex: 보험사, 금융권)








np배열과 리스트 비교


배열 초기화












Numpy 배열의 속성과 기본함수
- 요소마다마다 타입을 정할 때는 dtype ---- 요소에 해당
- 한꺼번에 요소의 타입을 바꿀 때는 astype (dtype과 같다고 볼 수 있음) ---- 요소에 해당
- type은 객체 자체의 타입을 리턴
shape는 함수인데 어디서는 필드처럼 쓰기도 함. -> 몇행몇열인지
reshape는 행과 열을 다시 바꿈.






랜덤함수와 seed값 설정하기
머신, 딥에서도 seed값과 똑같은 게 나옴.
매번 주지 않아도 되고 한번 정해주면 끝남.


참고) numpy.random 함수에서 suffle 함수 -> 데이터를 섞음. 나중에 딥러닝할 때, 컴퓨터가 학습을 제대로 안 해도 순서대로 외운 걸로만 풀 수 있음. 학습 제대로 하려면 몰려 있는 데이터를 섞어야 함.

