
Hayden's Archive
[Python-pandas] 데이터프레임(DataFrame) 생성 / 구조 / 컬럼명 변경 및 추가 / 조회(인덱싱, 슬라이싱) / 삭제 / 정렬 / 유용한 함수 본문
[Python-pandas] 데이터프레임(DataFrame) 생성 / 구조 / 컬럼명 변경 및 추가 / 조회(인덱싱, 슬라이싱) / 삭제 / 정렬 / 유용한 함수
_hayden 2020. 7. 13. 20:43< 차례 >
DataFrame 생성하기
DataFrame - 구조 확인
DataFrame - 컬럼명 변경 및 추가
DataFrame - 조회하기 (인덱싱, 슬라이싱)
drop() - 삭제하기
DataFrame - 정렬하기
실전데이터로 응용하기
알아두면 유용한 함수들

* DataFrame 생성하기
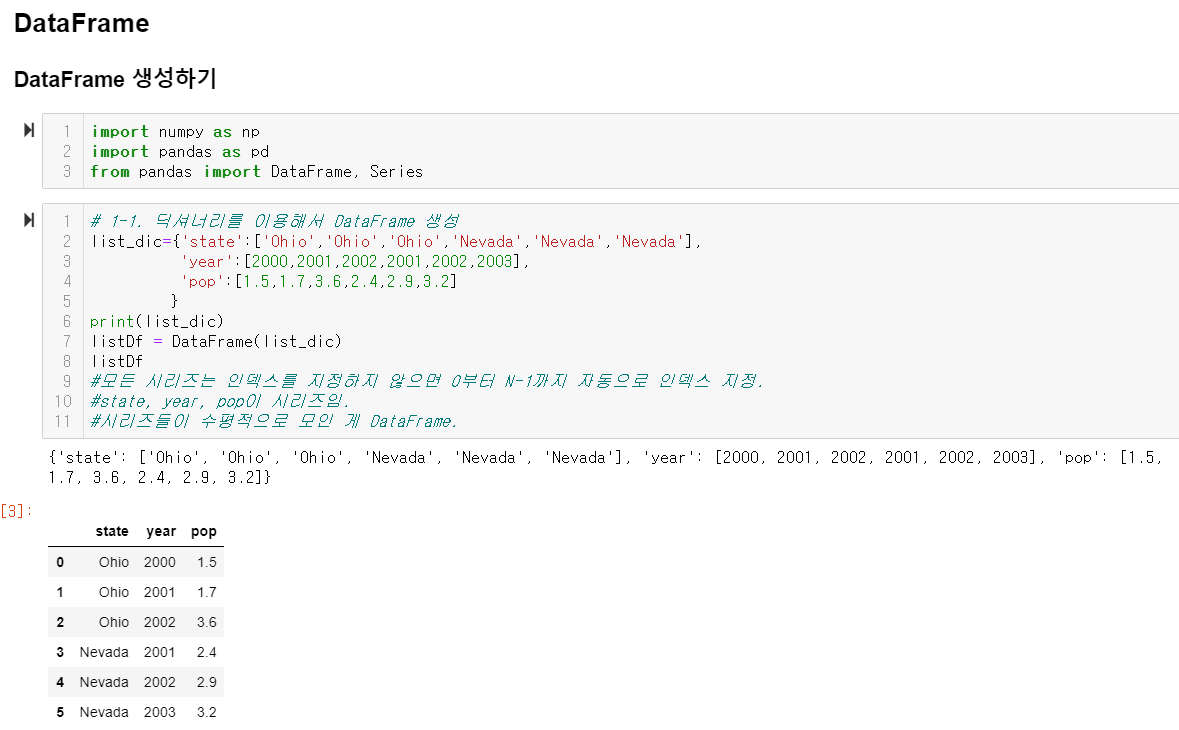


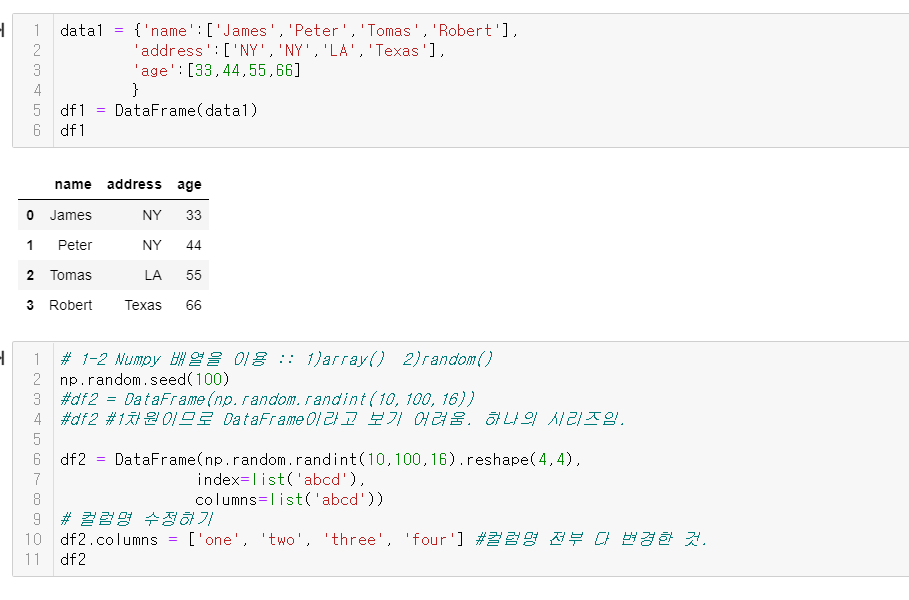

데이터를 로드해올 때 서두르지 말 것. 데이터가 어떻게 생겼는지 먼저 알고 들어가야 함. 그 데이터를 모르면 데이터 분석이 안 됨.
모델을 구축하는 것도 좋지만 어떤 데이터를 input으로 받아들이는지 알고 들어갈 것.
내가 분석하고자 하는, 학습시키고자 하는, 끌어오고자 하는 데이터가 어떤 모양인지 반드시 먼저 확인하고 코드 작성하기!
이 데이터가 어떤 데이터의 성격인지 알려면 이 데이터의 feature(특징=컬럼)이 무엇으로 이루어져있는지 알아야 함.
분석 전의 전략이 중요함. 기술이 고도화되면서 더 중요해진 건 인간적인 능력. 분석에 진입하기 전이 아이디어 싸움.
tips.csv ( https://www.kaggle.com/ranjeetjain3/seaborn-tips-dataset ) -> 데이터 분석할 때 거쳐가게 되는 유명한 데이터.
팁에 영향을 끼치는 요인... size => 몇명 왔는지

* DataFrame - 구조 확인




이 외에 T라는 속성이 있는데 T 속성은 DataFrame을 Transpose 한다.
(딥러닝에서 가중치(weight)라는 값이 중요함.
weight 값이 내가 의도하지 않았는데 T가 적용되어 나오는 경우가 생김. -> Transpose 되어서 나온 것.
출력 될 때 항상 Transpose돼서 출력됨. 행과 열이 뒤바껴서 출력.
데이터 분석할 때 Transpose를 쓸 일은 잘 없는데 인공지능에서 어떤 행과 열이 출력될 때 내부적으로 바뀌어서 나옴.)

* DataFrame - 컬럼명 변경 및 추가
리스트는 중복이 되므로 컬럼이 될 수 없음.
하지만 튜플은 컬럼이 될 수 있음.
Hierarchical Indexes -> 나중에 하게 될 것.



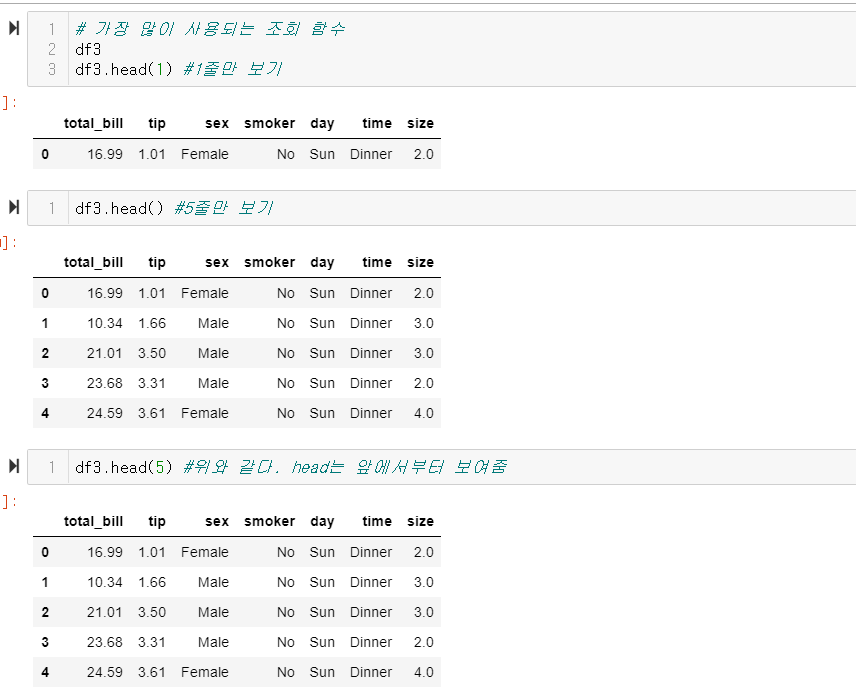
* DataFrame - 조회하기 (인덱싱, 슬라이싱)




* 굉장히 많이 씀. 알아야 함.
loc는 라벨(L)로 검색하는 것
iloc 인덱스로 검색하는 것
at 라벨로 스칼라값 검색
iat 인덱스로 스칼라값 검색



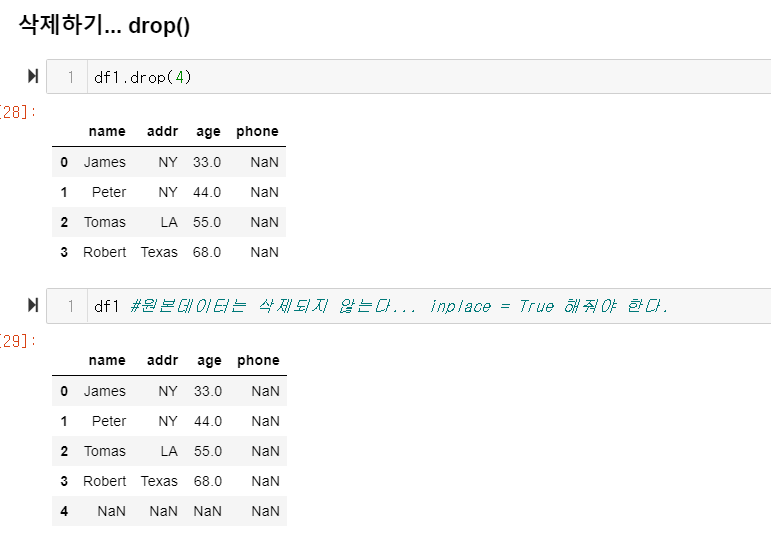
* drop() - 삭제하기

* DataFrame - 정렬하기


* 실전데이터로 응용하기




* 알아두면 유용한 함수들




참고 : 데이터프레임 스타일 주기 https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.io.formats.style.Styler.set_properties.html



