
목록Study (184)
Hayden's Archive
 [AI/딥러닝] Image Processing / Softmax Function / Loss Function
[AI/딥러닝] Image Processing / Softmax Function / Loss Function
CIFAR-10는 5만개의 Training Image가 있고 만개의 Test Image가 있음. 각각의 이미지는 32×32×3 * 32×32×3의 의미 32X32 => 이미지 세로와 가로(보통 정사각형으로 주어짐) 3 => 채널 수. (흑백은 채널이 1개, 칼라는 채널이 3개, RGB) 입력값인 X로 이미지가 들어옴. MNIST - 28X28X1 (0~9 손글씨 숫자. 검정색 바탕에 흰색글씨) 10개의 카테고리 랜덤함수 돌리면 10%의 확률 정답이 나오겠지만 딥러닝 알고리즘 돌리면 정확도 99.8%(사람보다 더 잘 맞힘) MNIST-Fashion CIFAR10 - 32X32X3 -- 정확도 99.3% 10개의 카테고리 MNIST보다 정보량이 더 많다.(=복잡한 입력이다) CIFAR100 - 정확도 93%..
 [AI/딥러닝] 딥러닝 도입( Segmentation / Computer Vision / Edge Detection / CNN / Classification / Cross-Validation )
[AI/딥러닝] 딥러닝 도입( Segmentation / Computer Vision / Edge Detection / CNN / Classification / Cross-Validation )
2020 유망 인공지능 스타트업 100 출처 : http://scimonitors.com/ai-100-2020-%EC%9C%A0%EB%A7%9D-%EC%9D%B8%EA%B3%B5%EC%A7%80%EB%8A%A5-%EC%8A%A4%ED%83%80%ED%8A%B8%EC%97%85-100%EA%B3%B3-%EC%9C%A0%EB%8B%88%EC%BD%98-10-%ED%8F%AC%ED%95%A8/ 2017년에는 한국 회사로 Lunit이 유일하게 100위 안에 든 적이 있다 ( http://www.techforkorea.com/2017/01/18/lunit-about-to-run-it-in-2017-the-only-korean-company-in-the-ai100-by-cb-insights/ ) 참고 : https..
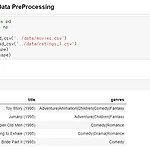 [AI/머신러닝] 코사인 유사도를 활용한 상품 기반 협업 필터링 코드
[AI/머신러닝] 코사인 유사도를 활용한 상품 기반 협업 필터링 코드
데이터 출처 : grouplens.org/datasets/movielens/ MovieLens GroupLens Research has collected and made available rating data sets from the MovieLens web site ( The data sets were collected over various periods of time, depending on the size of the set. … grouplens.org 1. DataLoading and Data PreProcessing 데이터를 가져와서 필요에 맞게 가공한다. 데이터 전처리 과정. 2. 영화와 영화들 간의 유사도 산출 - 코사인 유사도 활용 앞선 포스팅에서는 함수를 직접 구현했지만 여기서는 코사..
 [AI/머신러닝] 코사인 유사도를 통한 사용자 기반 협업 필터링 코드
[AI/머신러닝] 코사인 유사도를 통한 사용자 기반 협업 필터링 코드
Configuration Notation / Calculate Similarity (사용자 기반 / 상품 기반) 위의 코드들을 바탕으로 코사인 유사도를 리턴하는 함수를 만듦. 모든 사람의 유사도 검색 itertools를 통해 조합을 만든다. 모든 조합에 대한 유사도를 리턴하는 함수 평점 예측하기 사용자와 상품을 입력했을 때 평점을 예상하는 함수 모든 사용자와 상품에 대한 평점 검색
 [AI/머신러닝] 협업 필터링(Collaborative_Filtering)
[AI/머신러닝] 협업 필터링(Collaborative_Filtering)
추천 협업 시스템 -> 근래에 많이 오르내리고 있음. 협업 필터링은 비지도학습. 지도학습은 Feature와 Label을 같이 주지만 비지도학습은 Feature만 준다. 이 때의 데이터는 그룹 데이터. Clustering, Grooping된 데이터. 넷플릭스가 성장하게 된 가장 큰 배경 -> AI 기술, 그 중에서도 추천 협업 시스템. 참고1 : 1boon.kakao.com/scientist/700 참고2 : www.epnc.co.kr/news/articleView.html?idxno=83033 아이템 기반 추천(Item Based Recommendation) 영화들끼리의 유사도를 측정한 것을 바탕으로 사용자가 본 영화들을 바탕으로 영화들 사이의 유사도 검증 -> 그 사람이 보지 않은 영화 중에서 동일한 ..
 [AI/머신러닝] 최소제곱법(Least Square Method) / 평균 제곱 오차(Least Square Method)
[AI/머신러닝] 최소제곱법(Least Square Method) / 평균 제곱 오차(Least Square Method)
최소 제곱법(Least Square Method) 평균 제곱 오차(Mean Square Error = MSE) 예측값과 결과값 사이의 차이(오차)에 대한 제곱의 평균 Mean Square Error (MSE) 실습
 [C언어] C언어 입문 관련 코드
[C언어] C언어 입문 관련 코드
https://www.edwith.org/boostcourse-cs-050 [부스트코스] 모두를 위한 컴퓨터 과학 (CS50 2019) 강좌소개 : edwith - 부스트코스 www.edwith.org 요즘 하버드대학교 2019 CS50 강의를 듣고 있다. 이 강의는 컴퓨터 사이언스의 기본기를 다질 수 있는 명강의로 알려져 있는데 통학시간을 활용해서 재미있게 듣고 있다. 이 강의는 C 언어로 진행된다. C 언어는 2년 전에 잠깐 기초적인 부분만 배웠던 적이 있는데, 아무래도 C 언어보다는 자바, 파이썬을 훨씬 많이 사용해서 그 쪽이 더 손에 익다. 하지만 C 언어는 컴퓨터 과학의 뿌리가 되는 언어이기에, 비록 지금은 이외에도 할 일이 많고 배울 것도 많으니까 가볍게 배우고 있지만, 언젠간 C++과 함께 ..
 [AI/머신러닝] 선형 회귀(Linear Regression) / 손실 함수(Loss Function) / 미분 개념 / 경사하강법(Gradient Descent)
[AI/머신러닝] 선형 회귀(Linear Regression) / 손실 함수(Loss Function) / 미분 개념 / 경사하강법(Gradient Descent)
선형 회귀(Linear Regression) 회귀(Regression) - 선형 회귀( Linear Regression ) - 보통 회귀(Regression)은 선형회귀(Linear Regression)을 의미함. - 로지스틱 회귀( Logistic Regression ) - 회귀로 풀 수 없는 문제. 분류로 풀어야 함 => 0 아니면 1로 분류. 여기서 Signoid 함수가 나옴(뉴럴 네트워크에서 인간 생체에서 나옴...) 로지스틱 회귀( Logistic Regression ) 선형 회귀( Linear Regression ) Linear Regression에서는 Traing Data에서 보여지듯 공부시간에 대한 값 입력에 대해서 결과값인 시험성적이 연속적인 반면, Rogistic Regression에서..
 [AI/머신러닝] 편향(Bias)과 분산(Variance) / 앙상블 학습(Ensemble Learning) - 그레디언트 부스팅 머신(Gradient Boosting Machine) / Grid Search
[AI/머신러닝] 편향(Bias)과 분산(Variance) / 앙상블 학습(Ensemble Learning) - 그레디언트 부스팅 머신(Gradient Boosting Machine) / Grid Search
편향(Bias)과 분산(Variance) 앙상블 학습(Ensemble Learning) - 그레디언트 부스팅 머신(Gradient Boosting Machine) 그레디언트 부스팅 머신 관련 코드 Grid Search 굉장히 중요한 2개념 머신러닝의 에러 크게 2가지. Bias, Variance 편향(Bias) : 학습데이터를 충분히 표현할 수 없기 때문에 발생함. bias가 높다는 건 학습을 덜했다. underfitting 되어있다는 얘기 -> 학습 더 시키면 됨. 데이터 더 넣으면 됨. (근데 데이터가 없어서 못 넣으면... transform 해서 변형해서라도 넣어야 함. 그러면 기존의 데이터 가지고 데이터를 늘리는 효과를 얻을 수 있음. 딥러닝에서 배..
 [AI/머신러닝] 앙상블(Ensemble) / 랜덤 포레스트(Random Forest) / 오차행렬(Confusion Matrix)
[AI/머신러닝] 앙상블(Ensemble) / 랜덤 포레스트(Random Forest) / 오차행렬(Confusion Matrix)
앙상블(Ensemble) 랜덤 포레스트(Random Forest) 랜덤 포레스트(Random Forest) 코드 보기 오차행렬(Confusion Matrix) 앙상블(Ensemble) 앙상블과 랜덤포레스트 구분할 수 있어야 함. Random Forest is a Ensemble. 앙상블 알고리즘 중에서 가장 대표적인 게 랜덤포레스트 앙상블 알고리즘은 여러 개가 있는데 그 중 Random Forest 랜덤 포레스트(Bagging 방식), 그레디언트 부스팅 머신 Gradient Boosting Machines(Boosting 기법) 앙상블 러닝 참고 : https://brunch.co.kr/@chris-song/98 Ensemble: bagging, boosting.. 앙상블 학습의 핵심 아이디어들을 이해해..