
Hayden's Archive
[AI/머신러닝] 앙상블(Ensemble) / 랜덤 포레스트(Random Forest) / 오차행렬(Confusion Matrix) 본문
[AI/머신러닝] 앙상블(Ensemble) / 랜덤 포레스트(Random Forest) / 오차행렬(Confusion Matrix)
_hayden 2020. 7. 23. 18:56<목차>
앙상블(Ensemble)
랜덤 포레스트(Random Forest)
랜덤 포레스트(Random Forest) 코드 보기
오차행렬(Confusion Matrix)
앙상블(Ensemble)
앙상블과 랜덤포레스트 구분할 수 있어야 함.
Random Forest is a Ensemble.
앙상블 알고리즘 중에서 가장 대표적인 게 랜덤포레스트
앙상블 알고리즘은 여러 개가 있는데 그 중 Random Forest 랜덤 포레스트(Bagging 방식), 그레디언트 부스팅 머신 Gradient Boosting Machines(Boosting 기법)
앙상블 러닝 참고 : https://brunch.co.kr/@chris-song/98
Ensemble: bagging, boosting..
앙상블 학습의 핵심 아이디어들을 이해해봅시다. | 앙상블 러닝에 대해 공부하는 중 좋은 글이 있어서 번역했습니다. https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205 이 게��
brunch.co.kr
| 발전 방향 |
| 결정 트리 Decision Tree → 랜덤 포레스트 Random Forest → 그레디언트 부스팅 Gradient Boosting |

출처 : https://medium.com/analytics-vidhya/ensemble-models-bagging-boosting-c33706db0b0b
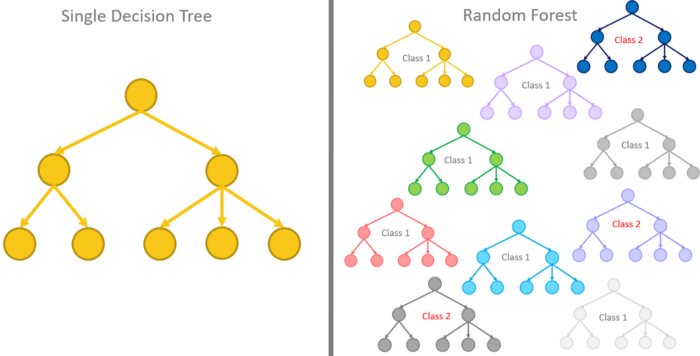
랜덤 포레스트(Random Forest)
30개의 속성 중에서 굳이 들여다 보지 않아도 되는 속성이 10개 정도 되는데 결정 트리로 하면 그 모든 것들을 일일이 다 들여다보게 되고 그러다 보니 overfitting에 빠지게 됨.
랜덤포레스트는 결정트리가 여러개 있는 것
Bagging(Bootstrap Aggregating) 기법

가방 생각하면 좋음.
무작위의 속성을 랜덤하게 뽑아서 가방 안에 넣음. 이 가방 하나하나가 결정트리들임.
여러 결정트리들을 모아서 다수결의 원칙에 의해, 혹은 평균에 의해 결정. 투표 결과를 얻는 것과 같음.
결정트리들을 굉장히 많이 둬야지 투표 결과가 나옴.
estimate가 높아야 한다.
결정 트리의 개수를 굉장히 많이 가져가야 함(기본 100개)
효과
overfitting될 가능성이 현저히 줄어든다.

하나하나 랜덤하게 뽑아진 결정트리를 estimator라고 함.
랜덤포레스트를 제대로 하려면 estimator를 많이 해야 함.
=> 단점 : 리소스를 굉장히 많이 먹음 -> 연산량이 굉장히 많아진다. 속도가 굉장히 오래 걸림 일반적인 컴퓨터 사양만으로 힘들 수 있음.
=> 단, cpu코어가 많으면 손쉽게 병렬 처리 가능. n_jobs 매개변수를 이용하여 사용할 코어 수를 지정 ( n_jobs=-1로 지정하면 컴퓨터의 모든 코어를 사용 )

별다른 지정을 하지 않으면 원래 데이터와 동일한 크기로 만들어짐.
estimator가 100개, 200개 이렇게 되는데 그걸 합하면 정확도가 높은 모델이 된다.
서로 다른 결정 트리가 만들어졌을 때 다양한 의견을 모아서 훨씬 더 정확도를 높일 수 있음.
그런데 하필 비슷비슷한 트리로만 나오면 다양하지도 않고 랜덤포레스트의 장점을 살릴 수 없긴 함.
78%, 58%, 93% -> 93%보다는 못 나오지만 평균 정도로는 나올 수 있다.
랜덤 포레스트에서
이진분류(Binary Classification), 다중분류(Multi-label Classfication) - 다수결에 의해 값이 결정됨.
회귀(Regression) - 범위에 있는 값, 선을 그리는 값 -> 다수결이 아니라 다수결에 해당하는 평균값으로 aggregation이 이루어짐
관련 Hyperparameter
n_estimators => 몇개의 결정 트리를 만들지 지정(보통 100개). 개수가 클수록 좋은 성능이 나옴.
max_features => 무작위로 몇개의 feature를 선택할 것인지.(정하지 않으면 기존의 feature와 동일한 개수)
-> 너무 작아도 문제고 너무 커도 문제. 그래도 작은 것보다는 큰 게 나음. 너무 작으면 overfitting이 문제가 아니라 학습이 안 됨.
랜덤 포레스트의 한계
랜덤 포레스트는 텍스트 데이터와 같이 매우 차원이 높고 희소한 데이터에는 잘 작동하지 않는다.
매우 차원이 높다 => feature가 굉장히 많다는 뜻
희소한 데이터 => row가 적은 데이터 / 예외적인 특이한 이상치 데이터
< 랜덤 포레스트(Random Forest) 코드 보기 >
DataSet Load

Model Accuracy 측정하기 #1. 직접 측정하기

Model Accuracy 측정하기 #2. 사용자 함수 정의해서 측정하기
여기서는 그냥 위에서 사용한 y_tuple을 가져다 썼음.

Model Accuracy 측정하기 #3. 라이브러리 이용해서 측정하기

오차행렬(Confusion Matrix) => 항상 2차원 행렬 형태로 나옴
뭐를 뭘로 혼동했는지 다 보여줌. 굉장히 유용한 시각화 도구.
Accuracy(정확도) : Matrix에서 대각선 부분
Precision(정밀도) : 모델이 True라고 분류한 것 중에서 실제로 True인 것의 비율(모델 관점)
Recall(재현도) : 실제값이 True인 것 중에서 모델이 True로 분류한 비율(실제값 관점)
정밀도, 재현도 둘 다 높은 게 좋은 것
정밀도와 재현도의 차이

precision을 끌어올리려는 편법이 되게 명료함.
맑은 날을 예측할 때 모델이 예측하는 정밀도를 끌어올리려면 날씨가 맑은 특성을 가미를 많이 하면 됨.
그래서 Recall이 Precision보다 더 신뢰도가 높다
Model Accuracy 측정하기 #4. Confusion Matrix





Confusion Matrix를 DataFrame으로 나타내고 Seaborn의 Heatmap으로 시각화




